What is Cross Validation?
Cross validation is a statistical method used to evaluate the performance of a model or algorithm in quant trading, as well as in other fields such as machine learning and data science. It can be used to test or train how well a model generalizes to unseen data by dividing the data into multiple subsets and iteratively training and testing the model on different combinations of these subsets.
In the algorithm development process, the cross validation method can be used to reduce the chance of overfitting the strategy to the data, which can lead to poor performance in live trading.
How does Cross Validation work?
The method divides the original data into multiple subsets between training, testing then a validation set. By doing this, it will increase the robustness of the final algorithm as the model parameters are tuned overtime as if the algorithm is developed using live market data.
As you expect, as the algorism is being trained on the training set, and tested independently on the testing and validation sets for overfitting, if there are signs of overfitting, then the effectiveness of the strategy will decrease meaningfully in these 2 additional sets of data.
In quantitative trading, cross validation can be applied to assess the predictive power of trading strategies or models before deploying them in live trading. The process typically involves the following steps:
- Divide the historical data into a number of folds or subsets, often maintaining the chronological order of the data.
- For each fold, train the trading model on a combination of the remaining folds and test its performance on the current fold. This way, the model is always tested on data it has not seen during the training phase.
- Aggregate the performance metrics from each fold to estimate the overall performance of the model.
Cross-validation helps ensure that a model is robust and can perform well on unseen data, leading to more reliable and consistent trading results.
Example of Cross Validation
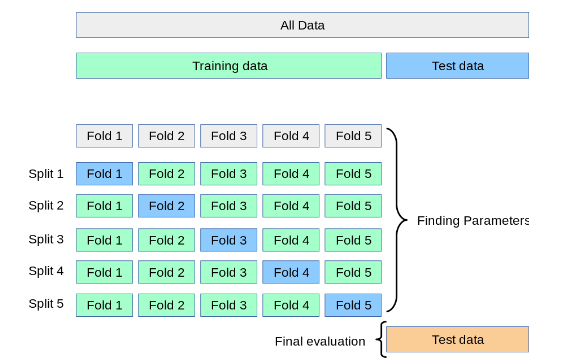
source: scikit-learn
The downside of using Cross Validation
By using cross-validation, quants can minimize the risk of overfitting their models to historical data. But in order to increase effectiveness, the data series has to be broken up over multiple cross validation series so the algorithm ends up being tested multiple times for overfitted ness.
The downside of this approach, as you expect, requires the data series to be of sufficient quantity that after breaking it down into the various components, the sample size of each individual fold is still meaningful enough to test the strategy against.
One way of extending the data series in testing a generalized model is to use prices of different data series that are similar to the target market of the strategy.
- For example, if you are testing the model on the S&P 500, the same can be applied to NASDAQ or Russell 2000 index as these are highly correlated and similar price series to an extent.
- If the model is tested on individual stocks, then stocks in the same industry can be used to expand the data set. For example, Goldman Sachs and Morgan Stanley in the financial sector. Apple, Google and Meta in the technology sector.